
Navigating The AI Game Board As A GPT Wrapper
Now that the foundation model roadmap is clear, there's never been a better time to build AI applications


Two years after ChatGPT's release, the AI game board has finally settled into place.
The foundation model landscape has now whittled down to a handful of well-funded giants – OpenAI, Anthropic, Google, Meta, and xAI – with clear paths to more powerful AI by scaling pre-training, compute efficiency, and agent development.
At the application layer, we’ve also seen the first successful applications built on these models, with companies like Abridge, Harvey, and Perplexity leading the way. This marks a stark contrast to a year ago, when building with AI felt like playing with quicksand. Early markets were oversaturated, architectural patterns were unclear, and foundation models rendered entire application categories obsolete with regularity. Even the concept of a separate "app layer" was theoretical, as full-stack products like ChatGPT, Github Copilot, and Midjourney dominated.
Today, we’re entering a new phase in AI application development that promises to elevate the once-dismissively labeled "GPT wrappers” – provided they can continue to keep out of the way of the foundation models they sit on. Three key learnings from this past year shape this perspective:
We’re not at the “end of scaling,” but have only reached the start. While frontier models have scaled a millionfold – from GPT-1's preschool-level to GPT-4's intern-level intelligence – this is just phase one. The next stage will require billion-dollar clusters with 100K+ H100s – infrastructure far beyond today's capacity. Some see the required capex and the looming data wall as the end of scaling, but these hurdles merely narrow the field to those with the capital and talent to participate. Frontier labs and cloud hyperscalers are already investing for these multiple additional leaps in scale. For app startups, the implications are that many products that don’t work with today’s models will soon work with tomorrow’s more powerful AI.
Models will not just get smarter, but more agentic too. Smarter models are no free lunch for AI apps. Reasoning models like OpenAI’s o-series models demonstrate a powerful new vector for scaling, but the increase in intelligence is only the first step to a broader ambition to build long-horizon agents that will increasingly compete with many of today’s agentic apps. Over the coming years, the models won’t need any external scaffolding but will become agents themselves – capable of computer use and task automation over hours and days.
Tomorrow’s AI app winners need to differentiate on more than technical workarounds. Because today’s models still come “hobbled” out of the box, the first generation of AI app companies succeeded by enhancing them with search, web access, and agentic scaffolding. As these features become baked into the next generation of models, applications will need to find new advantages through their data, workflows, and UX.
The State of Play in AI & The Research Lab Roadmap
The biggest overhanging question for AI applications has always been what the frontier labs would do in the next six months to a year. In the past, the jump from GPT-3 to GPT-4 and Claude-1 to Claude-3 introduced so many new emergent capabilities, it was difficult to extrapolate the type of intelligence GPT or Claude-Next could bring about.
However, as the market has matured and major labs have released successive model iterations, we've gained better insight into both the trajectory of improvements and the key levers driving progress.
Today, the models are not just getting better but predictably, reliably better in a trend that has created a more stable foundation for AI app development. Looking forward, this newfound predictability should continue as all the major AI labs have converged around three core vectors for further progress: physical compute, compute efficiency, and agentic capabilities.
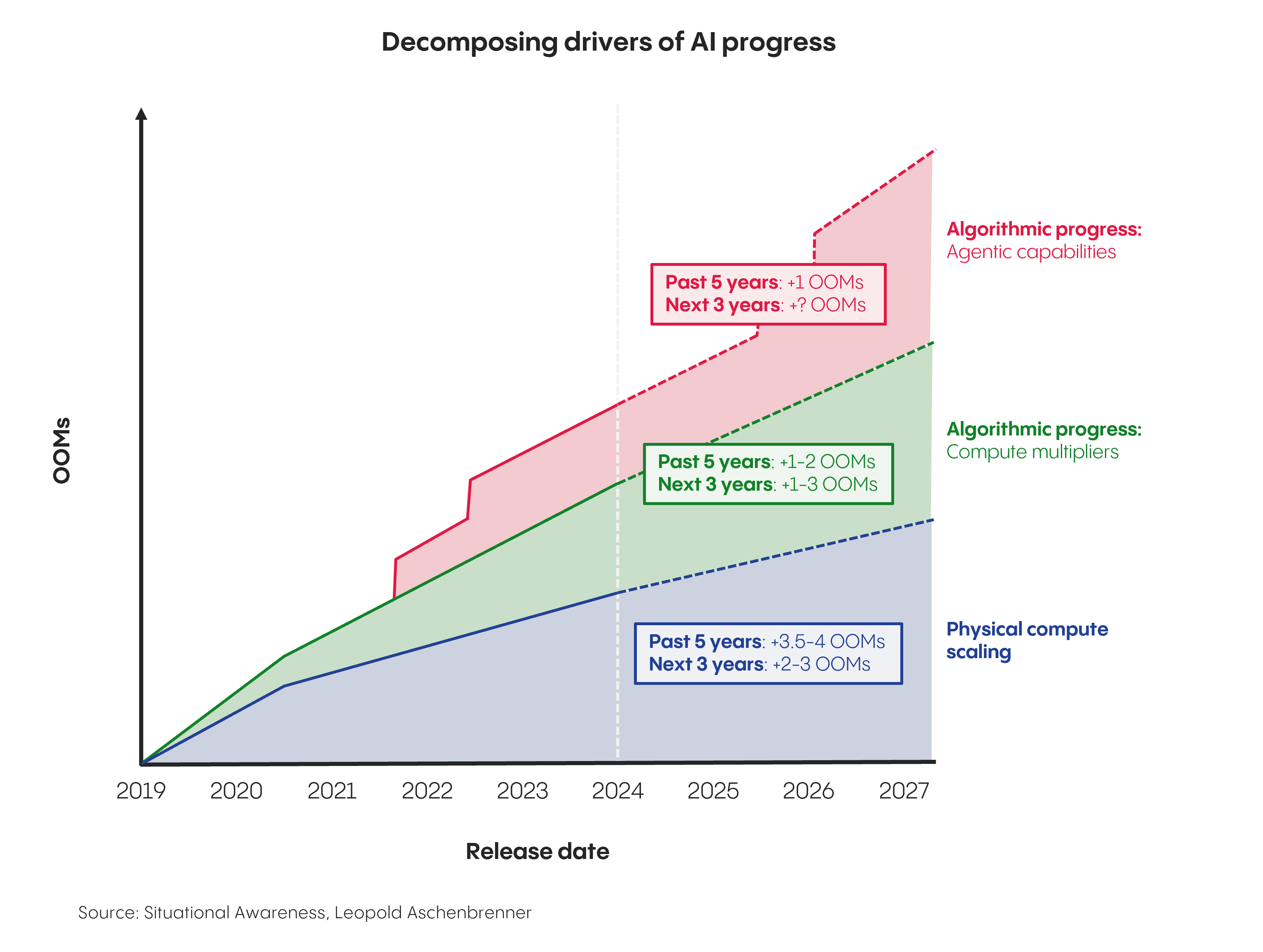
1. Physical compute scaling
AI progress today is primarily driven by scaling pre-trained models, a paradigm that began with GPT-2 in 2019 and the discovery of scaling laws – which showed that larger models trained on more powerful computers reliably produce greater capabilities and intelligence.
At the time, researchers observed that the scaling laws already held true across 7 orders of magnitude (OOM) of compute increases. Since then, new capabilities have continued to scale with model size with remarkable consistency. As frontier models increased another 3.5-4 OOM from GPT-2 to GPT-4, intelligence grew in parallel from that of an elementary schooler to that of a college intern.
Today, all of the large AI labs remain committed to further scaling up this vector even as concerns about a data wall grow louder – which the large labs aim to overcome via synthetic data, reasoning traces, and human annotation.
Microsoft, Amazon, Google, and Meta will spend over $260 billion dollars this year alone on capex, much of it for bigger data center buildouts that can enable +1 OOM scaling for their partner foundation models. Meanwhile, even more ambitious projects like OpenAI’s $500 billion Stargate training cluster aim to enable another GPT-2-to-GPT-4-sized leap (+3 to +6 OOMs) beyond GPT-4’s current intelligence levels over the coming years.
2. Algorithmic progress - compute multipliers
Frontier AI labs can scale intelligence either by increasing raw compute or via algorithmic efficiency ("compute multipliers") that use existing compute more efficiently. DeepSeek recently made headlines by applying their own compute multipliers to train a nearly state-of-the-art model 8x more cheaply, mirroring Claude-3.5 Sonnet’s own 10x efficiency gains vs GPT-4 a year prior.
But for the purposes of scale, frontier labs think about compute multipliers from the other end – enabling greater intelligence while holding cost constant. Anthropic CEO Dario Amodei estimates algorithmic improvements now contribute about a 4x annual compute multiplier (+0.5 OOMs) to LLM progress, up from 1.7x in 2020.
3. Algorithmic progress - agentic capabilities
The final and potentially most powerful vector for AI progress moving forward lies in reinforcement learning (RL) for agentic tasks. While the frontier labs spent much of 2019-2024 focused on scaling pre-training, models like OpenAI's o-series represent a fundamental shift from single-stream predictions to chains of thought with intermediate logic. Large-scale RL in post-training ensures correctness at each step, preventing cascading errors and enabling increasingly complex reasoning.
But this new paradigm signals something even more significant than just more intelligence: research labs are systematically "unhobbling" their foundation models from current limitations. Today's models operate in isolated boxes – they're primarily text-based, lack browser access and tool use, and are limited to short dialogues. Through advances in reasoning, multimodality, and computer interaction, labs aim to transform these models into fully embodied virtual collaborators capable of engaging in browser-based tasks spanning hours or days – fundamentally reshaping both their form factor and how AI companies must build on top.
The Winners and Losers From GPT-Next
As foundation models gain multiple orders of magnitude in intelligence over the coming years, AI application companies stand to benefit the most. Features that don't work with today's models may suddenly become viable with the next leap in intelligence.
In fact, we’ve already seen evidence of how better models move markets. Before Claude 3.5 Sonnet's release in June 2024, all AI coding startups combined generated less than $15 million in ARR. But when Sonnet emerged as the most capable coding model, companies like Cursor, Cognition, and Stackblitz quickly adopted it – scaling more than 10x as a group in less than 6 months, and gaining significant market share against Copilot, which was still using the older Codex model.
Stackblitz CEO Eric Simons put it bluntly: "Claude 3.5 Sonnet is the enabling technology that made this product possible, period."

Smarter and more agentic AI models won't universally benefit all AI applications though. Instead, they'll create distinct winners and losers.
The most vulnerable companies are those whose primary competitive advantages rely on compensating for current LLM limitations through web and tool integrations, algorithmic workarounds, or agent frameworks that guide model behavior. Companies heavily invested in these temporary technical solutions are essentially betting against further AI progress – progress that frontier labs are aggressively pursuing.
The risks of this approach are already visible. Even in the brief evolution from GPT-3.5 to today's models, several early AI apps have already had to abandon overengineered architectures built to bridge gaps in previous foundation model capabilities.
Consider Codestory: the company initially developed a sophisticated Monte Carlo Tree Search framework to guide their AI coding agent's decision-making, only to later find that simply running parallel, unconstrained single trajectories produced superior results – letting the foundation model itself guide solution exploration rather than imposing algorithmic constraints.
Codestory called it “re-learning the bitter lesson,” noting: "For the better half of this year, we figured algorithmic smartness would yield better results. We were left amazed at the learning that scaling inference could and does yield results which are state-of-the-art."
The pattern is clear. The AI applications that will thrive with smarter and more agentic LLMs are those with architectures that embrace what LLMs are best at – brute force scaling. The unreasonable effectiveness of this conceptually simple approach doesn’t just apply in pre-training, but also at inference time, with massive parallel execution enabling agent swarms to solve problems in minutes that previously required hours of manual effort.
This architectural approach is already proving successful across multiple domains – from site reliability engineering (Traversal) and security incident investigation (Crogl) to pen testing (Xbow) and revenue operations (Rox). As AI capabilities continue to advance, we expect this pattern to replicate across even more domains.
Building Enduring AI Applications Out of GPT Wrappers
As foundation models continue to see exponential leaps in capability over the coming years, there's never been a better time to build AI applications that bridge the long last mile between the coming models and messy real world use cases.
With enterprise buyers already demonstrating strong demand and the AI game board finally crystallizing, entrepreneurs have a generational opportunity to transform today's GPT wrappers into tomorrow's enduring AI applications.